Taking the average tone
Today I wanted to see what the average frequency of a song would sound like with no spectrum analysis or separation. I had a hunch that it would end up sounding like garbage, and I was totally right.
If you took the average color of a beautiful painting, it would likely turn out muddy brown. Today, I created the audio equivalent:
Steve Reich’s Music for 18 Musicians:
Kill the Noise remix of KOAN Sound’s Talk Box:
These first tones were generated using the powerful, free, cross-platform audio software Audacity and a cool lisp-y language called Nyquist. Since Audacity lets you run Nyquist scripts on hand-selected audio segments, this first bit was quick and dirty:
- Drag the desired audio file into Audacity
- On the left side of the window, click the arrow1 beside the track’s name
- Select “Split Stereo to Mono” from the resulting dropdown
- Double-click the top track to select it
- In the menu bar, click Effect > Nyquist Prompt…
- Enter the following into the prompt:
(setf f0 (aref (yin s 33 93 4400) 0))(setf fl (truncate (snd-length f0 ny:all)))(setf mean-f0 (snd-fetch (snd-avg f0 fl fl op-average)))(format nil "Mean Fundamental Frequency:~%~a ~~~a"(step-to-hz mean-f0)(nth (round mean-f0) nyq:pitch-names))
- If you’re using a recent version of Audacity, check the “Use legacy (version 3) syntax” box at the top of the prompt2
- Let it run and remember the output frequency
- Keeping the track selected, click Generate > Tone… in the top menu
- Input the frequency that was generated in step 7
- Repeat 4 - 9 on the bottom track
- Click the arrow again and select “Make Stereo Track”
Its hack-y and too manual, but it was enough to show me that I definitely didn’t want to keep going down this path. From a spectrum this wide, across such a long duration, the tones I was getting didn’t correspond to any individual sound in the original song. At best, i’d found a roundabout way to generate spooky alien noises.
Measures of central tendency
Let’s quickly go over mean, median, and mode.
- Mean, often called average, is the sum of all values in a set divided by the number of values in the set
- Median is the middle-point in a set ordered by magnitude
- Mode, the ugly cousin of median, is the most commonly occurring value in a set
Given the following set of numbers: { 8, 4, 6, 6 ,8, 4, 8 },
and rearranging them in order: { 4, 4, 6, 6, 8, 8, 8 },
we observe a median of 6, a mode of 8, and a mean of… 6.29?
Why mean sometimes sucks
Our result above demonstrates why my “average” tones sound nothing like their original tracks. After taking the mean of a set, there’s no guarantee that your result will be a member of the set. Just as 6.29 isn’t part of the set { 8, 4, 6, 6 ,8, 4, 8 }, the tones that I generated weren’t really part of their respective songs. In the process of finding the “average” tone, we lost touch with the most important part of the song; its individual notes.
More resolution!
After showing this to a friend of mine, he suggested that I take the average frequency of each quarter-note instead of taking it across the entire song. Remember, this in no way addresses the problem that we just went over.
“It will still sound terrible,” I said, “the drums and bass and vocals are going to be mixed into some weird middle-ground tone”.
“Yeah,” he replied, “but it’ll be a different kind of terrible.”
I couldn’t argue with that. It would be near-impossible to use my old method on a per-note basis since that would require hand-selecting each quarter-note, so I decided to do a better job at it using Python.
Python has some awesome modules for audio analysis, but the underlying math can be pretty intimidating. Though a lot of the heavy-lifting is abstracted away for us, it’s important to have a grasp of a few ideas before diving in. Since we’re trying to find the average frequency of a tone, let’s start by figuring out how to isolate a frequency in a signal!
Finding frequencies
When we talk about frequencies in music, we’re referring to the frequency at which a pressure wave needs to repeat to make our ears hear a certain note3. Audio signals are usually represented as a pressure wave over time since that’s how microphones and speakers understand sound. When multiple frequencies are played at the same time we end up with a more interesting waveform that represents the composite of its individual parts. If we’re really clever, we might be able to pick out characteristic waveforms of different sounds just by how they look.
A time-domain representation like this allows us to recognize the structure of a song and to move sections around intuitively. One trade-off of representing audio like this is that filtering or modifying frequency content becomes really difficult as you add more sounds. To play with frequencies, we’re going to move from the time-domain into the frequency-domain.
The Fourier Transform
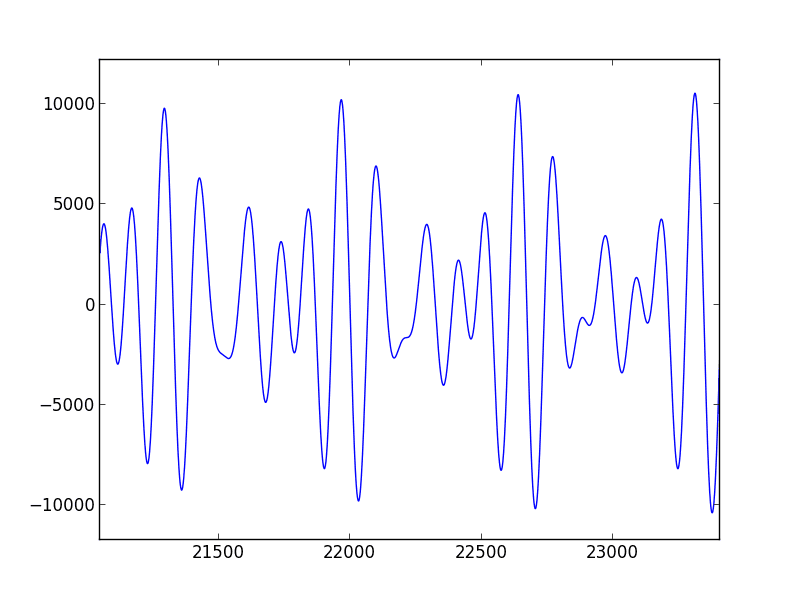
The Fourier transform allows us to move from the time or spatial representations of signals that we’re used to into the frequency domain. Calculating the Fourier transform of an audio signal gives you a new representation that looks like this:

Here we have frequency on the x-axis and magnitude on the y-axis. The Fourier transform breaks a signal down into its component frequencies; since the diagram above shows high magnitudes at about 260Hz (C), 330Hz (E), and 390Hz (G), it looks like we’ve got a C Major chord on our hands. Easier than trying to figure out the chord from the time-domain, huh?
Wikipedia has the best gif I’ve ever seen for this:

Got it.
If you didn’t understand all of that, don’t worry. The important thing to remember is that we need to figure out how powerful each frequency is, and the Fourier transform helps us get there.
First we import a few modules4:
import numpy as np, composerimport scipy.io.wavfile as wavimport scipy.fftpack as fftfrom itertools import izip_longest
Next, we use scipy’s wavfile.read to return the audio’s sample rate and audio contents.
import_rate, import_data = wav.read('wav/flute.wav')import_bpm = 62 #manually set
…and we’re all set up. Finding the average frequency of an audio clip is going to be the meatiest part of this problem, and it’s not too bad with the help of scipy and numpy:
def average_frequency(rate, data):sample_length = len(data)k = np.arange(sample_length)period = sample_length / ratefreqs = (k / period)[range(sample_length / 2)] #right-side frequency rangefourier = abs(fft.fft(data * np.hanning(sample_length)) / sample_length) #normalized, not clippedfourier = fourier[range(sample_length / 2)] #clip to right-sidepower = np.power(fourier, 2.0)return sum(power * freqs) / sum(power)
Essentially, we’re being passed in some audio content and its corresponding sample rate, throwing it through a Fourier transform, and returning the average frequency as heard by us. The magnitudes alone don’t mean much physically, so we square them to represent the power of each frequency before averaging the range.
Next we need to split the song into chunks to send through the average_frequency function. Since we know our sample rate (samples / second) and tempo (beats / minute) already, we can figure out how many samples make up a beat and slice it up.
def quarter_note_frequencies(rate, data, bpm):notes = []beat_counter = 0slice_size = rate * 60 / bpm #samples per beatbeats = len(data) / slice_size #beats per songfor slice in grouper(data, slice_size, 0):beat_counter += 1print unicode(beat_counter * 100 / beats) + '% completed'notes.append(average_frequency(rate * 1.0, slice))return notes
Here we’re using a function called grouper that lets us slice up the data. It’s described in depth in itertools’ Recipes section.
We’re getting really close! Now we just need a function to write some frequencies to a wav file,
def create_wav(rate, data, bpm):duration = 60.0 / bpm #seconds per beatwav.write('wav/flute_avg.wav', rate, np.array(composer.generate_tone_series(data, duration), dtype = np.int16))
…and a line to call that file…
create_wav(import_rate, quarter_note_frequencies(import_rate, import_data, import_bpm), import_bpm)
And we’re done! The whole thing (including my composer module), is on Github.
Let’s hear what it sounds like:
Them Crooked Vultures’ Bandoliers:
The Chemical Brothers’ Another World:
Wow! Still terrible! Who would’ve thought!
Conclusion
It’s probably safe to say that this isn’t going to be the next-big-thing in music. That said, it was really cool that some songs (see “Another World” above) output a repeating melody different from their own. It’s entirely predictable, but I still enjoyed being able to hear it.
I hope to make a Part Two some day where I explore some nicer-sounding alternatives, but I’m hanging up my signal processing hat for a while to focus on other things. One very fun project would be to take a moving window through a song and record only the highest magnitude frequencies at each time-step. Doing this, you could subvert the skewing caused by loud, quick tones (snare drum) and artifacts caused by strange envelopes or effects. It isn’t a big step from where we got to today, and I’m confident that with enough tuning it could roughly isolate a song’s melody.
